python多线程threading
目录
threading介绍与简单使用
threading介绍:
threading模块threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:threading.currentThread(): 返回当前的线程变量。threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:run(): 用以表示线程活动的方法。start():启动线程活动。join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。isAlive(): 返回线程是否活动的。getName(): 返回线程名。setName(): 设置线程名。
程序示例:import threading
import threading def thread_job(): print("this is an added Thread ,number is %s" %threading.currentThread()) def main(): added_thread = threading.Thread(target=thread_job) # 定义一个新的线程,指定一个任务给target added_thread.start() # 开启线程 print(threading.activeCount()) print(threading.enumerate()) print(threading.currentThread()) if __name__ =='__main__': main()
程序运行结果:
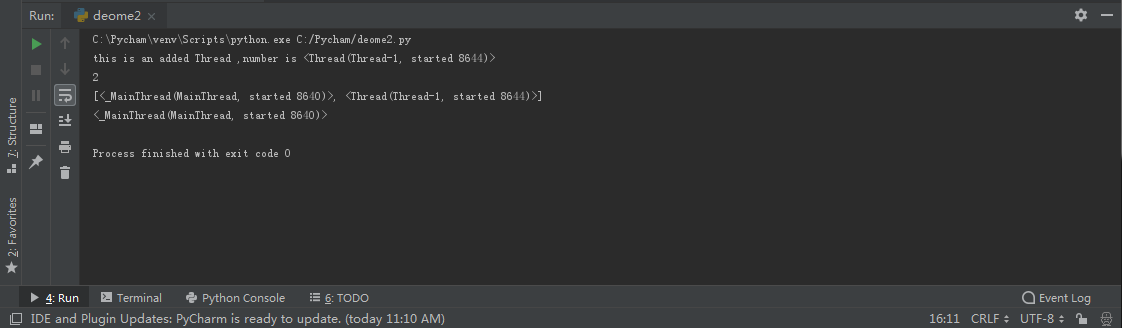
第一个输出是当前线程,这个是我们开启的线程
第二个输出的是在正在运行的线程的数量
第三个输出返回一个包含正在运行的线程的list,包含主线程和开启的线程
第四个输出是当前线程,最后只剩下主线程
join功能
join功能介绍:
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
当我们有一个程序功能必须等到开启的线程执行完以后,才能运行主线程,就可以使用这个功能。
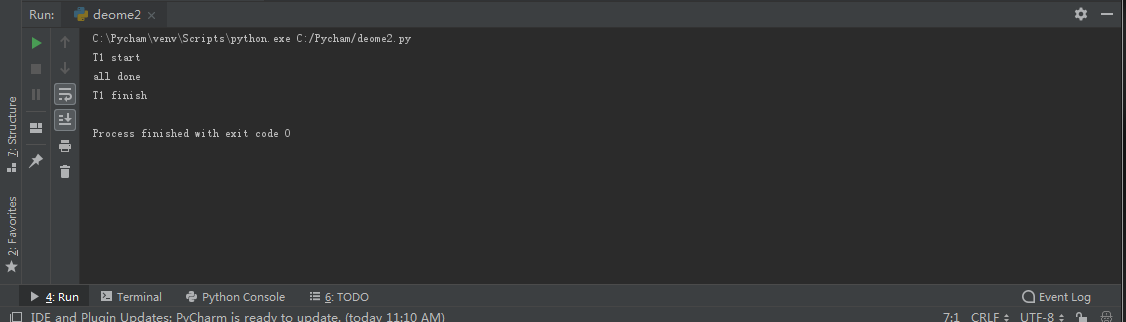
不加join的情况,这种情况下,以下例程序看来,主线程运行更快,我们看看结果
程序示例1:
import threadingimport timedef thread_job(): print("T1 start") for i in range(10): time.sleep(0.1) print("T1 finish")def main(): added_thread = threading.Thread(target=thread_job,name = 'T1') #定义一个新的线程,指定一个任务给target added_thread.start() #开启线程 print("all done") if__name__=='__main__': main()
程序运行结果:
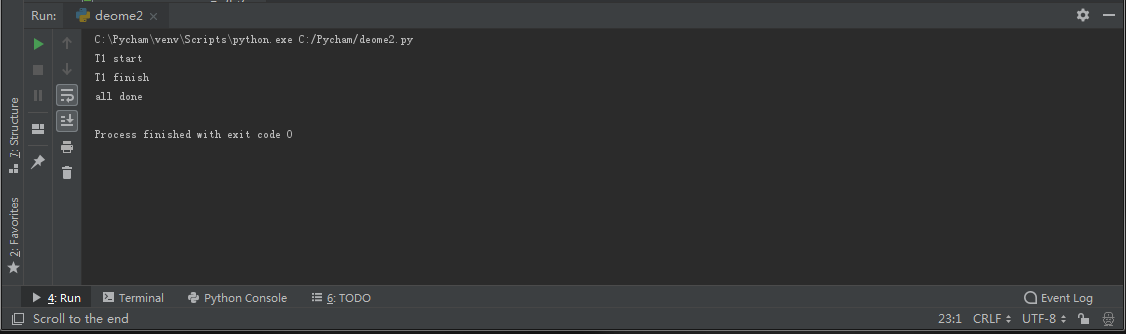
加join的情况,等待我们开启的线程执行完以后才能运行主线程。
程序示例2:
import threadingimport timedef thread_job(): print("T1 start") for i in range(10): time.sleep(0.1) print("T1 finish")def main(): added_thread = threading.Thread(target=thread_job,name = 'T1') #定义一个新的线程,指定一个任务给target added_thread.start() #开启线程 added_thread.join() print("all done")if __name__ == '__main__': main()
程序运行结果:
queue功能
线程之间的通信
queue功能:
线程优先级队列( Queue)Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。Queue 模块中的常用方法:Queue.qsize() 返回队列的大小Queue.empty() 如果队列为空,返回True,反之FalseQueue.full() 如果队列满了,返回True,反之FalseQueue.full 与 maxsize 大小对应Queue.get([block[, timeout]])获取队列,timeout等待时间Queue.get_nowait() 相当Queue.get(False)Queue.put(item) 写入队列,timeout等待时间Queue.put_nowait(item) 相当Queue.put(item, False)Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号Queue.join() 实际上意味着等到队列为空,再执行别的操作
先进先出模式:get与put的阻塞
#get卡import queue #线程队列q = queue.Queue() #线程队列的对象q.put(12) #往队列里面放入数据q.put("hello")q.put({ "name":"yuan"})#先进先出#如果队列为空,取值就会被阻塞,只有当队列有值才能取到值while 1: data = q.get() if data: print(data) print("--------")#put卡import queue #线程队列q = queue.Queue(3) #队列里可以存储几个值q.put(12) #往队列里面放入数据q.put("hello")q.put({ "name":"yuan"})q.put(1) #只能存储3个值,这里缺试图存储第四个值,只有当有别的线程取走一个值,才能存储进值while 1: data = q.get() if data: print(data) print("--------")
在get与put阻塞的时候报错
q.put(1,False)q.get(block=False)
先进后出模式
import queueq = queue.LifoQueue()q.put(12)q.put("hello")q.put({ "name":"yuan"})q.put(1)while 1: data = q.get() if data: print(data) print("--------")
优先级模式
import queueq = queue.PriorityQueue()q.put([3,12]) #往队列里面放入数据q.put([2,"hello"])q.put([1,{ "name":"yuan"}])while 1: data = q.get() if data: print(data) print("--------")
下面演示了在多线程中怎么返回线程中的运行结果,因为不能使用return返回! 使用Queue.get()和Queue.put()方法
程序示例:
import threadingfrom queue import Queuedef job(l,q): for i in range(len(l)): l[i] = l[i] + 1 # 对列表里每一个值加一 q.put(l) # 把计算的结果保存到queuedef main(): q = Queue() # 使用queue存放返回值 threads = [] # 创建进程列表 data = [[1, 2], [3, 4], [4, 5], [5, 6]] # 创建四个进程并启动添加到进程列表里面 for i in range(4): t = threading.Thread(target=job, args=(data[i], q)) t.start() threads.append(t) # 把所有线程都加到主线程中 for thread in threads: thread.join() # 创建存放结果的列表 results = [] # 把结果保存到results列表中 for _ in range(4): results.append(q.get()) print(results) if __name__ =='__main__': main()
程序运行结果:

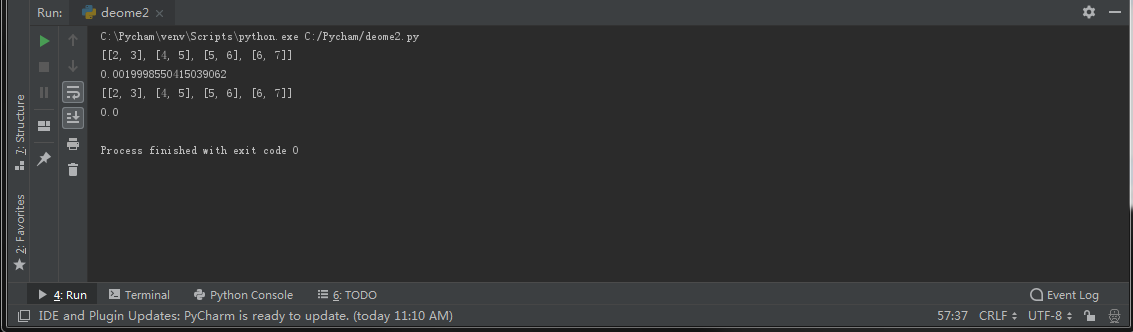
比较多线程和不使用多线程的运行速度
我们知道python中实现多线程其实是把正在运行的线程锁住,这时候其他线程就不会运行,就是在同一时间里只有一个线程在运行,在不断地切换线程中就可以实现多线程。
下面我使用多线程和不使用线程,来做同样的运算工作,看谁运行的更快。
import threadingfrom queue import Queueimport timedef job(l,q): for i in range(len(l)): l[i] = l[i] + 1 # 对列表里每一个值加一 q.put(l) # 把计算的结果保存到queuedef normal(l): results = [] for i in range(len(l)): l[i] = l[i] + 1 results.append(l[i]) return resultsdef main(list): q = Queue() # 使用queue存放返回值 threads = [] # 创建进程列表 # 创建四个进程并启动添加到进程列表里面 for i in range(4): t = threading.Thread(target=job, args=(list[i], q)) t.start() threads.append(t) # 把所有线程都加到主线程中 for thread in threads: thread.join() # 创建存放结果的列表 results = [] # 把结果保存到results列表中 for _ in range(4): results.append(q.get()) print(results)if __name__ =='__main__': data1 = [[1, 2], [3, 4], [4, 5], [5, 6]] data2 = [[1, 2], [3, 4], [4, 5], [5, 6]] start1_time =time.time() main(data1) print(time.time()-start1_time) start2_time = time.time() result = [] for i in range(len(data2)): result.append(normal(data2[i])) print(result) print(time.time()-start2_time)
运行结果:
在pycham和网上的在线编译器上都运行过,大致上来多线程运行的速度要快不少

lock锁
lock.acquire() 锁住
lock.release() 解锁
#这种方式:开启100个线程,每个线程执行的时间很短,虽然线程之间有竞争关系,但在同一时刻里只有一个线程工作,每个线程执行的速度要比cpu切换的速度要快,线程的执行之间无缝连接。# import threading# def sub():# global num# num -= 1## if __name__ == '__main__':# threading_list = []# num = 100# for i in range(100):# t = threading.Thread(target=sub)# t.start()# threading_list.append(t)# for i in threading_list:# t.join()# print("全部执行完成")# print("num =",num)
#这种方式:和前面不一样的是,time.sleep(0.1)的时间比cpu切换的时间慢,这样当一个线程还没有机会执行num = temp - 1,就被下一个线程拿到cpu的执行权了,import threadingimport timedef sub(): global num temp = num time.sleep(0.1) num = temp - 1if __name__ == '__main__': threading_list = [] num = 100 for i in range(100): t = threading.Thread(target=sub) t.start() threading_list.append(t) for i in threading_list: t.join() print("全部执行完成") print("num =",num)
#上面的问题中,因为time.sleep(0.1)的或称超过cpu切换时间,我们不需要让它切换:# import threading# import time# def sub():# global num# lock.acquire()# temp = num# time.sleep(0.1)# num = temp - 1# lock.release()## if __name__ == '__main__':# threading_list = []# num = 100# lock = threading.Lock()# for i in range(100):# t = threading.Thread(target=sub)# t.start()# threading_list.append(t)# for i in threading_list:# t.join()# print("全部执行完成")# print("num =",num)#
同步对象
# import threading## event = threading.Event //插件一个event对象## event.wait() //如果没有设置标志位,调用wait()就会被阻塞,设置了标志位就不会被阻塞# event.set() //设置标志位# event.clear() //清除标志位# event.isEvent() //判断是否设置了标志位# event用来控制线程之间的执行顺序,在一个线程改变标志位,在另一个线程就能捕捉到标志位的变化import threadingimport timeclass Worker(threading.Thread): def run(self): event.wait() #event.set = pass,就不会继续阻塞 print("worker:哎。。。命苦") time.sleep(0.5) event.clear() #清空标志位 event.wait() #没有标志位就会被阻塞 print("worker:下班了")class Boss(threading.Thread): def run(self): print("Boss:今天加班到10点") print(event.isSet()) #False event.set() #设置标志位 time.sleep(5) print("Boss:可以下班了") print(event.isSet()) event.set() #再一次设置标志位,阻塞效果消失if __name__ == '__main__': event = threading.Event() List = [] for i in range(5): t1 = Worker() t1.start() List.append(t1) t2 = Boss() t2.start() List.append(t2) for i in List: i.join()
信号量
信号量控制最大并发数,在一段时间内有多少线程可以运行。
import threadingimport timeclass myThread(threading.Thread): def run(self): if semaphore.acquire(): print(self.name) time.sleep(3) semaphore.release()if __name__ == '__main__': semaphore = threading.Semaphore(5) threading_list = [] num = 100 for i in range(100): t = myThread() t.start() threading_list.append(t) for i in threading_list: i.join() print("全部执行完成") print("num =",num)
解决死锁:递归锁
# import threading# import time### class MyThread(threading.Thread):## def actionA(self):# A.acquire()# print(self.name,"gotA",time.ctime())# time.sleep(2)## B.acquire()# print(self.name,"gotB",time.ctime())# time.sleep(1)## B.release()# A.release()## def actionB(self):# B.acquire()# print(self.name, "gotB", time.ctime())# time.sleep(2)## A.acquire()# print(self.name, "gotA", time.ctime())# time.sleep(1)## A.release()# B.release()## def run(self):# self.actionA()# self.actionB()## if __name__ == '__main__':# A = threading.Lock()# B = threading.Lock()# List = []# for i in range(5):# t = MyThread()# t.start()# List.append(t)# for y in List:# y.join()# print("All end")##这里只有一个锁,r_lock内部是一个计数器,内部从0开始计数,当acquire一次,计数器就会加1,release就会减1#所以,无论何时只有一个线程拿到这个锁,用这个锁,无论再做多少次加锁、解锁的操作都是对一个锁的行为。#内部计数大于0,别的线程就无法拿到锁!!!#执行过程:五个线程竞争,有一个线程拿到cpu执行权,这个线程执行actionA,拿到r_lock锁,计数器加一,打印一次,然后再加一次锁,计数器再加一#线程顺序释放两把锁,这个线程是要继续往下执行actionB,r_lock锁加1,内部计数器大于0,其他线程也就拿不到这把锁了,也就保证了无论何时只有一个线程能拿到这把锁!#死锁的情况中,我们使用了两把锁,这里我们只使用了一把锁,而内部维持着多把锁。import threadingimport timeclass MyThread(threading.Thread): def actionA(self): r_lock.acquire() print(self.name,"gotA",time.ctime()) time.sleep(2) r_lock.acquire() print(self.name,"gotB",time.ctime()) time.sleep(1) r_lock.release() r_lock.release() def actionB(self): r_lock.acquire() print(self.name, "gotB", time.ctime()) time.sleep(2) r_lock.acquire() print(self.name, "gotA", time.ctime()) time.sleep(1) r_lock.release() r_lock.release() def run(self): self.actionA() self.actionB()if __name__ == '__main__': r_lock = threading.RLock() List = [] for i in range(5): t = MyThread() t.start() List.append(t) for y in List: y.join() print("All end")